Tablecruncher Tutorial: Find Duplicates in a CSV File using Macros
Published: Mar 1, 2019 — Updated: Jul 21, 2025
A typical task when working with CSV files is to find and process duplicates, very often to delete them. Tablecruncher provides Javascript as a builtin macro language. This tutorial shows how to find and delete duplicated entries in a column. We’re using flagged rows to highlight the rows that have duplicates. This allows you to check them before deleting or even exporting those duplicates into its own CSV file.
Step 1: Our initial file
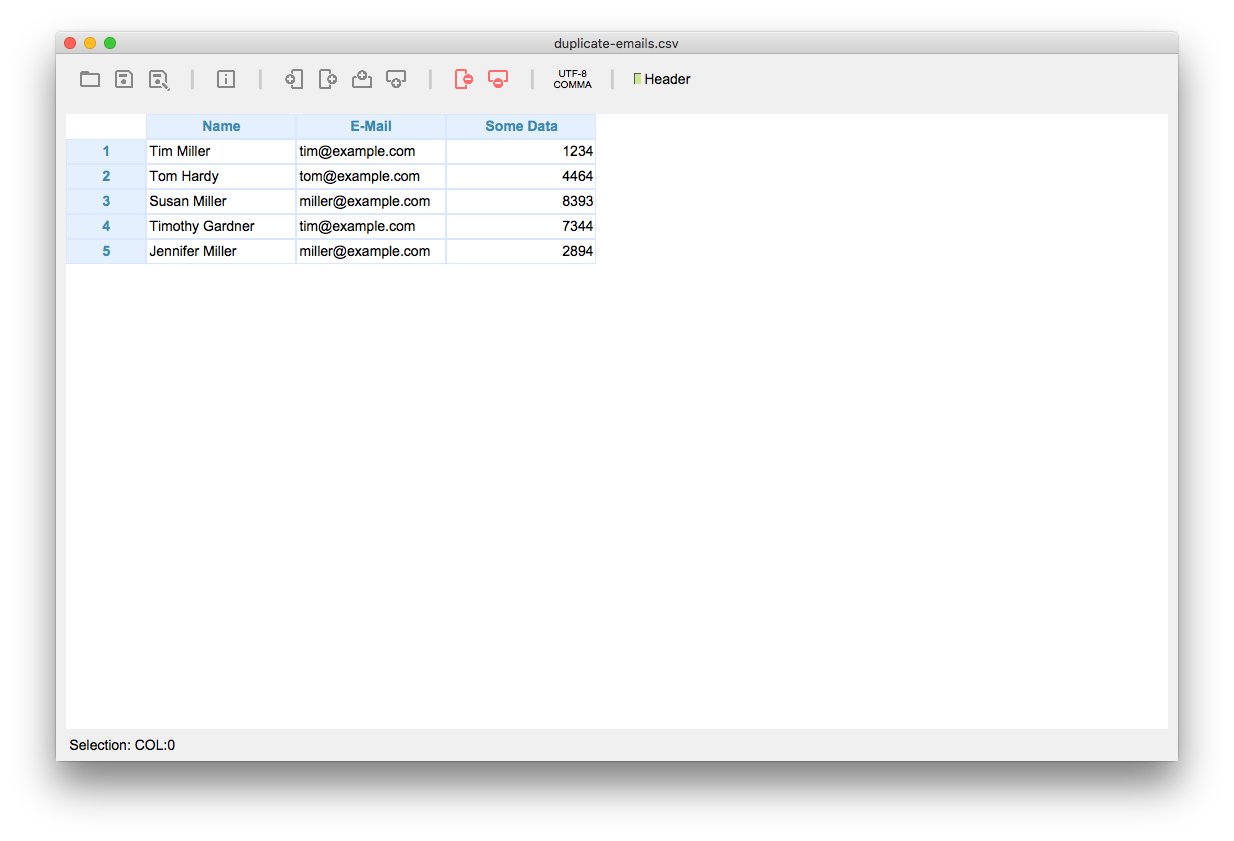
This is our initial file that serves as an example for this tutorial.
Step 2: Sort the column with the values to check for duplicates
Now we’re going to sort the column which possibly contains duplicate entries. This step ensures all rows with duplicates are grouped together. To achieve this, just right-click the header of our column “E-Mail” or use Data > Sort … and choose the correct column from the dropdown.
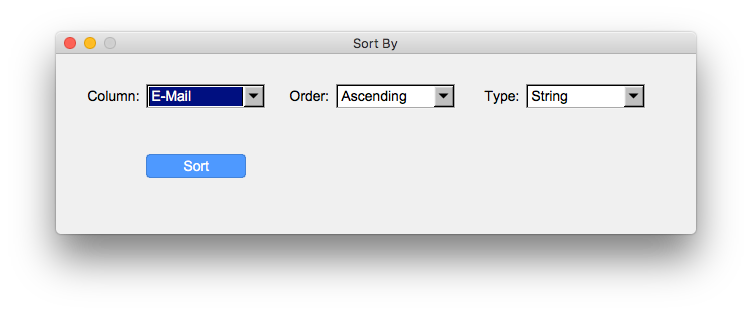
After clicking Sort the table is sorted by the value of the chosen column.

Step 4: Select column
We select our sorted column by clicking on its column header. (You don’t have to select the whole column. Just make sure the selection is in the column that we check for duplicates.)

Step 5: Flag lines with duplicates
With our sorted column selected, we choose Macro > Execute Macro …, click the little “+” sign and add a new macro with the name “Find Duplicates”. Insert the following code into the source area of the macro editor.
// Flag duplicate rows
for( r = 1; r<_ROWS; ++r) {
var cell = getString(r,COLMIN);
var prevCell = getString(r-1,COLMIN);
if( cell == prevCell ) {
flagRow(r);
}
}
This code loops over all rows (_ROWS contains the number of rows), leaving out the first row. In cell we store the content of the recent cell, while in prevCell there’s the content of the cell above it. If cell equals prevCell we’ve found a duplicate, so we flag that row using flagRow(r).

Just click execute and the macros flags all rows containing duplicates:

Step 6: Delete all flagged rows
To finally delete the duplicates, click Data > Delete Flagged Row(s) ….

Of course, before you delete the duplicates, you can check them to make sure you’ve flagged the correct duplicates only. Or you can use Data > Export Flagged Row(s) … to store your duplicates in their own CSV file as a backup or for further processing.
Final thoughts
This tutorial should give you some ideas on how to implement your data cleansing tasks utilizing the power of the builtin Javascript language. You can learn more about Tablecruncher’s Javascript macros in our documentation.
If you’ve questions regarding this tutorial or if you have ideas for further tutorials, don’t hesitate to contact me by e-mail: info@tablecruncher.com